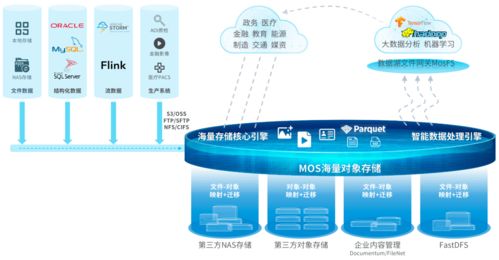
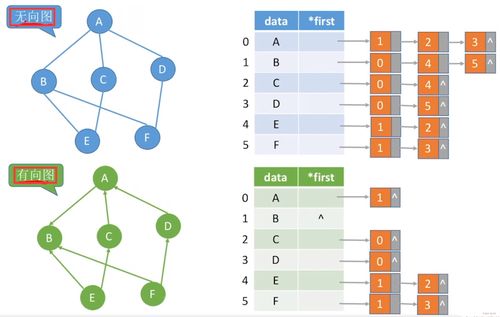
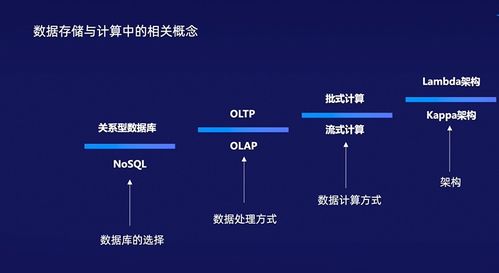
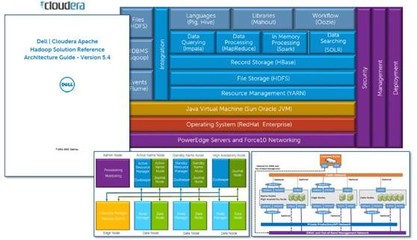
Apache Hudi 中表的存储类型及其在数据分析和存储服务中的应用
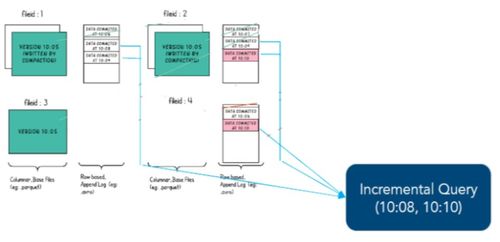
Apache Hudi(Hadoop Upserts Deletes and Incrementals)是一个开源的数据湖框架,旨在简化大数据处理中数据的增量更新、删除和查询。在 Hudi 中,表的存储类型是其核心概念之一,它决定了数据如何组织、存储和访问。Hudi 主要提供两种存储类型:Copy-on-Write(COW)和 Merge-on-Read(MOR)。这些存储类型对数据分析和存储服务的效率、延迟和资源使用有直接影响。
我们来详细解释 Hudi 的两种存储类型。Copy-on-Write(COW)类型在写入数据时直接更新现有文件,每次更新都会生成新的文件版本,这确保了数据的一致性,但可能增加写入延迟和存储开销。COW 适用于读多写少的场景,因为它提供优化的查询性能,数据始终处于可读状态。例如,在数据分析服务中,如果需要对数据进行频繁的查询和报告,COW 类型可以快速响应,同时保持数据的 ACID 特性。
相比之下,Merge-on-Read(MOR)类型将更新和删除操作记录在增量日志文件中,而不是立即合并到底层数据文件中。这减少了写入延迟,因为不需要每次更新都重写整个文件,但读取时可能需要合并日志和基础文件,从而增加读取延迟。MOR 类型适用于写多读少的场景,例如实时数据摄取或流处理服务,它允许高效的数据更新,同时支持近实时的查询。在存储服务中,MOR 可以帮助管理高吞吐量的数据流入,减少存储成本,因为基础文件可以保持不变,仅通过日志处理变更。
在数据分析和存储服务中,选择合适的 Hudi 存储类型至关重要。对于数据分析应用,如果重点是快速查询和低延迟读取,COW 类型更合适,因为它提供优化的列式存储格式(如 Parquet),与 Apache Spark 和 Presto 等查询引擎无缝集成。相反,对于存储服务,特别是处理实时数据管道或需要频繁更新的场景,MOR 类型更能平衡写入性能和存储效率。Hudi 还支持事务性保证和增量查询,这进一步增强了其在数据湖架构中的实用性,帮助组织构建可靠的数据平台。
Apache Hudi 的存储类型为数据管理和分析提供了灵活性。COW 和 MOR 各有优势,用户应根据具体用例(如批处理分析、实时流处理或混合负载)来选择。通过合理配置,Hudi 可以显著提升数据湖的性能和可扩展性,支持现代数据驱动的业务需求。
如若转载,请注明出处:http://www.xspush.com/product/21.html
更新时间:2025-11-29 02:32:26